The trailer advert for Hemo Sapiens: Awakening is now available on YouTube as a 60-second short.
I think I’ll stick to writing. The cover-making wasn’t half bad, but video production with Generative AI is not all it’s cracked up to be.
I considered Artlist.io, but I didn’t want to spend the cash. Maybe next time.
Let me know what you think. You can find a copy of the book from a link on my announcement page. If you get a copy, leave a review. It helps to appease the algorithm gods.
Here thee, hear thee. It’s about time. Hemo Sapiens: Awakening is finally published and available for purchase reading.
It’s been quite the journey. It started in August 2023 as a diversion from another project, but it ended up taking precedence.
Per the blurb on Amazon, the book is about this:
Genetically engineered and cloned in secret, the “Hemo Sapiens” have lived isolated on a farm in Manchester for decades—until their extraordinary nature is revealed.
Suddenly these “Bloodsucking Intelligent Humans” find themselves persecuted as dangerous outsiders. As hysteria escalates and mobs attack, the fiercely loyal and mostly innocent family fights for acceptance while struggling to find answers about their shadowy origins and uncertain destiny.
A genetics professor’s rash scientific revelation sets off an explosive chain reaction entangling ethics, prejudice and politics. At stake is nothing less than the family’s human rights—and what it truly means to belong.
Can these reluctant pioneers overcome fear to integrate into a society both fascinated and repulsed by their very existence? This thought-provoking saga confronts what diversity, progress and being human entail in an increasingly hostile, high-tech surveillance state that is meant to protect but may also oppress.
Amazon Marketing Blurb
The book currently available in many global regions as hard cover, paperback, or Kindle. I am currently working on the audiobook version, which should be available by March 2004.
For the sake of simplicity, below are links to the various marketplaces: Australia, Brasil, Canada, France, Germany, India, Italy, Japan, Mexico, Netherlands, Poland, Spain, Sweden, United Kingdom, and United States. Not all formats are available in all regions. As of today, this is the availability.
Hard Cover
(ISBN: 979-8872481942, Case Laminate 6″ x 9″, gloss)
I’ve just received my first Beta feedback from Hemo Sapiens: Awakening. I’ve hired three readers and engaged two, so I’ve got more to go.
As I wrote recently, I’ve been using AI to review my work, and I’ve been waiting for flesh and blood humans to give me their opinions.
My Beta reader is Enrico B from South Africa. My next reader is from the UK. I found them both on Fiverr.com, a site I’ve successfully used for music collaboration in the past. Although your results may vary, it’s a generally inexpensive way to get quality results. I hired Doni from Indonesia to design my title and subtitle.
Judge the quality for yourself. I happen to like it. I was going to commission the rest of the book cover, but I opted to do that myself.
Enrico provided me with a summary report as well as an annotated markup of my manuscript. Beta reading is not developmental editing or copyediting, so I wasn’t expecting line edits, but he did provide commentary on most chapters. In my case, his focus was on pacing and adding narration to fast-paced dialogue exchanges. In most cases, he advised my to slow my roll, but I’ll wait to see what the next reader writes. My style is rather curt and quick, and perhaps Enrico wants to savour a bit more. I feel that his advice is constructive. I just don’t know how much I’ll implement—probably at least a little.
In Hemo Sapiens: Origin, I am mixing French and English dialogues and tags. The challenge I am having is switch between the languages.
For example, see this passage:
« Où est maman ? » Camille asks Claire just as her parents come into view. « Maman » she exclaims, starting to weep again. « Papa. » She receives his hug.
French and English dialogue and speech markers work differently. I I were depicting large swathes of each language, I’d simply apply the specific language rules, but I am mixing it up, and that creates challenges. I haven’t seen any good examples how to present this.
Some obvious differences are the guillemets « » in French versus ‘ ‘ in English. In French, ? and ! are spaced after the sentence, and all content internal to guillemets is offset by leading and terminal spaces. Another big difference is that guillemets offset dialogue blocks whereas English uses speech marks to identify each speaker’s dialogue.
Referencing the example above—in English for English readers—, if I were to convey the content using French presentation rules, it might look something like this:
« Where’s mum ? Camille asks Claire just as her parents come into view.
— Mum, she exclaims, starting to weep again.
— Dad. She receives his hug. »
Notice that the entire block is enquoted. I’ve considered this, but I feel it will not track well for English readers, who are used to the speaker-reference convention.
Also, I really want to set off the French language content, and the guillemets serve that function.
Regarding dialogue, French and English punctuation rules are similar enough, but there aren’t many cases of a comma (virgule) following a speech mark given the convention. To my eyes, it looks better inside the marks, but it feels off. The Oxford English style guide suggests not even using commas to separate the dialogue from the tag, but I don’t see that much in the wild.
Again, referencing the example above, one can see how I am solving this at the moment.
At first, I indicate the French dialogue by guillemets and employ French punctuation rules followed by a dialogue tag and descriptive content.
« Où est maman ? » Camille asks Claire just as her parents come into view.
Next, I use the English format, but I replace quotation marks with guillemets. I’ve omitted the trailing comma—after ‘Maman’—in this example.
« Maman » she exclaims, starting to weep again.
Finally, since ‘Papa’ expresses a complete thought, I enclose the full stop within the guillemets. Rather than a dialogue tag, I opt for a stand-alone sentence.
« Papa. » She receives his hug.
When I write mixed language copy, I usually identify a foreign language in italics, but I didn’t choose to do this for French dialogue. Firstly, because I am already using italics for other foreign words, e.g. Latin; secondly, because these also depict internal dialogue/monologue, so I don’t want to create too many visual design patterns.
Has anyone else solved this problem? I’d love to know.
As for the cover image, Dall-E 3 still can’t quite figure out words and can’t spell in French or English. I share it if only for the absurdity of it. Here was my other choice:
It seems that spelling and grammar checking in Microsoft Word might use some improvement.
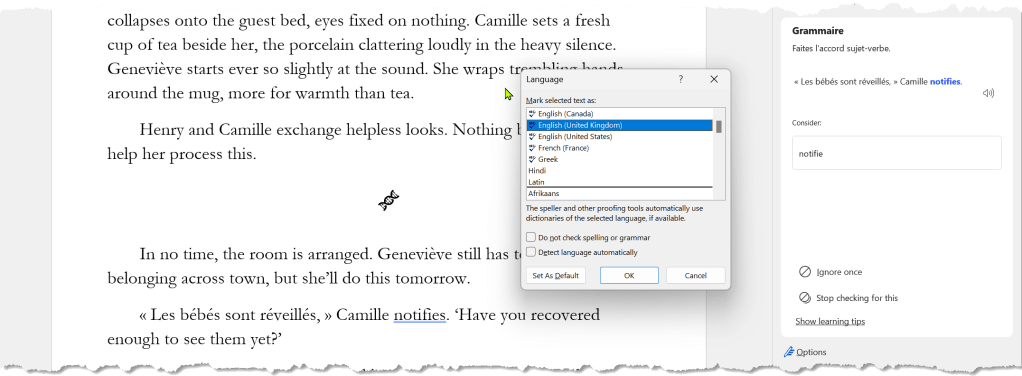
Here is a segment from a chapter from the first draft of Hemo Sapiens: Origin. Notice the last paragraph. I’ve written some dialogue in French with a tag in English. followed by more dialogue in English. This is my attempt to provide guidance to readers who don’t read French, so they can still maintain the context The problem is that Word doesn’t do a great job of accepting language markers. In this case, ‘notifies’ is underlined as being incorrect because Word, despite being informed otherwise, sees this as being French.
I wish I could just highlight a phrase and select the language from a context menu. Up front, I could specify that I am using languages X, Y, and Z, so I am not burdened with a laundry list of language options.
Another interesting thing to me is that there are separate auto-correct dictionaries per language. This makes sense, but it creates a burden to have to signify the language to let Word know which one to use. In my case, I tend to add accented words to autocorrect because I use a standard English-language QWERTY keyboard, and Windows/Word doesn’t make compounding diacritical marks very easy.
For example, a common entry might be ‘bien sûr’ for ‘bien sur’. I also get guillemets « » from << and >>, respectively.
Sadly, the ‘Detect language automatically’ feature isn’t very reliable either, so I leave it unchecked instead of having it misidentify languages.
I just noticed a typo in the screen shot. Word missed that ‘belonging’ should be plural, but probably thinks it’s a verb rather than a noun. Other AI tools make similar semantic errors.
I love origin stories. In fact, my next writing project is an origin story.
But that’s a tale for another day. This post is to reveal the reason for the pseudonym, Ridley Park. This story starts in Delaware, where I lived from 2018 until 2023. I often travelled up 95 North to get to the aeroport or Philadelphia. On this drive, a road sign often caught my eye: Ridley Park.
I cached the name to memory, thinking it might make for an interesting character name. Each trip, this was further imprinted and reinforced.
In April 2022, I was writing another novel. The topic is beyond controversial. In fact, I haven’t yet found anyone who’s not abhorred by the concept, so I know I have to publish it when I finish it. Because of the subject matter, I felt a pen name was in order, and I decided to use Ridley Park. To be fair, the unfinished book is set in Philly, so the name felt particularly apt.
I’ll guess that most of us have heard of the film director, Ridley Scott. The connexion is beyond obvious. It maintains the same cadence.
I’ve never visited Ridley Park. All I know is that it’s a suburb south of Philly, and I’ve borrowed the name. In the end, as it turns out, the question was never ‘Who is Ridley Park?’ Rather, it’s ‘Where is Ridley Park?’ all along.
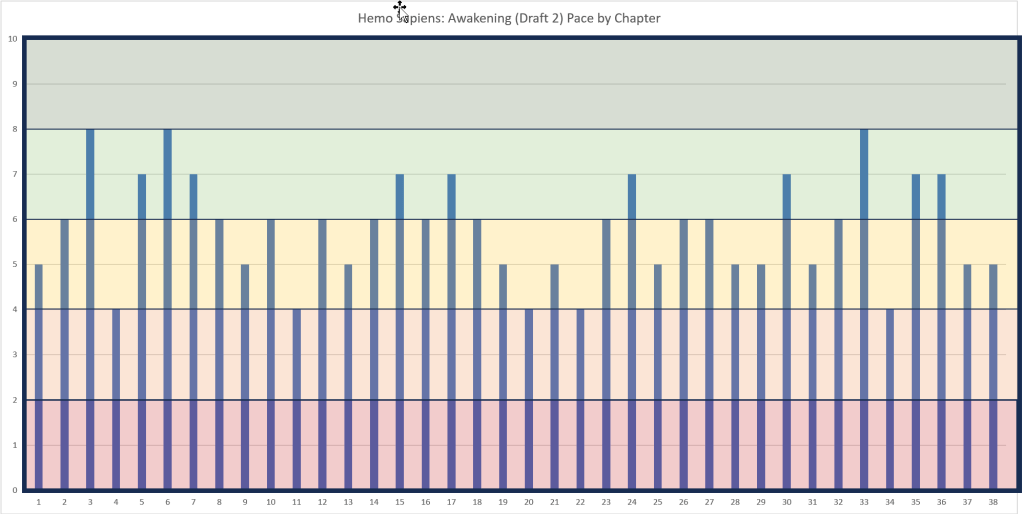
As I review Hemo Sapiens: Awakening and work on the second draft, I asked Claude 2.1 to analyse the pacing of each chapter. This is the result.
Legend
1-2: Very slow, not much happening plot-wise
3-4: Moderately slow pace with some plot development
5-6: Steady pace with a balance of action and exposition
7-8: Fast-paced with lots of plot advancement
9-10: Very fast-paced, intense action or events
The positive news is that I don’t have anything a the glacial pace of 1 and 2. I do have some slothful 4s, but not threes. I’ve got quite a few 5s and 6s, a respectable amount of 7s and a few 8s, with no break-neck 9’s and 10s.
My goal will be to review the 4s to determine if they are intentional. At first glance, I don’t have any consecutively slow chapters, although having sequential 4s and 5s might be problematic. For example, the four chapters 20 to 22 might be too much of a lag in the middle. I’ll need to keep page count into account as ell. There are a handful of very short chapters, so if a few of those are slow, I might just accept it.
As percentages, we’ve got 13% of 4s (5), 29% of 5s (11), 29% of 6s (11), 21% of 8s (3), so it feels OK—generally a steady to fast-paced novel. The pace seems to ebb and flow, so the reader should be able to remain engaged. Obviously, the slower parts of for character development and description, but none of this is just meandering pointlessly.
In the end, this works for me as a diagnostic tool. This is the first time I’ve tried it. It seems like the assessments are fair. As I rewrite, I can try to tighten some of the slower section and see if the pace picks up.
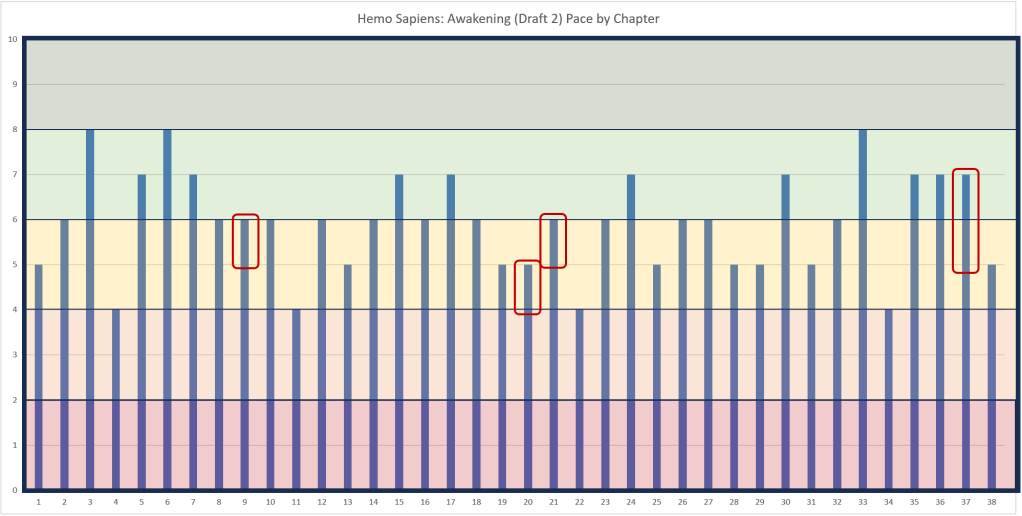
UPDATE: I reworked chapters 8, 20, 21, and 37, increasing the pace of 5 to 6, 4 to 5, 5 to 6, and 5 to 7, respectively. Chapter 37 was boosted to 7 when I added new information to set up downstream conflict. Unfortunately, the conflict won’t payoff until book 3, since the next book,2, will be a prequel—Hemo Sapiens: Origin—, after which this story will continue.
I still have revisions unrelated to pacing, but I’ll measure them as they come and hope not to stall any. At this point, the average is about 6 (not displayed). Of 38 chapters, 89 per cent of the chapters are steady to fast. 11 per cent are moderate—only 4 of them—and none are slow.
I feel this is a good starting place, and I’d be happy to land here.
I was chatting with Claude about continuity and flow. I had written an intentionally awkward sex scene and it critiqued some of the activities and, mainly, dialogue. When I asked for clarification, among other things, it returned this:
reworking the banter into flirtier foreplay might heighten the heat of the scene without awkward moments.
— Claude 2.1
Essentially, this was the apology.
Artificial Intelligence doesn’t grasp cultural knowledge. It doesn’t fully grasp irony. It’s like trying to understand a joke from another culture. Without the cultural background, it won’t make any sense.
In another chapter, I asked Claude to analyse a passage that contained a tongue in cheek reference. It didn’t understand why it was humorous.
In yet another, I made a situational reference, and Claude found it amusing, but when I asked why, it was for a reason unrelated. It reminded me of Steve Buscemi’s schoolboy scene on 30 Rock—well out of place.
Now that the first draft of Hemo Sapiens: Awakening is done, I can let it marinate for a few days before I return to polish it up for Beta readers. Meantime, I can cleanse my palate and concentrate on other matter like cover art. Here’s the third or fourth draft. I know what direction I’m looking for. I was thinking of commissioning a cover, but I might just go it on my own.
I think I’m going with an 9″ x 6″ form factor, so this would be the aspect ratio. I used OpenAI’s Dall-E 3 to render the eyes as well as the overlay with Greek characters. I may have made it too transparent, so I might need to pull it up a few clicks.
Interesting enough, I am compositing in PowerPoint of all things and exporting to PNG. I usually use Paint Shop Pro, but this may be good enough. I still need to compose the back cover and the spine.
My paginated draft comes in at about 320 pages. It was 256 unpaginated pages. There are 38 chapters, and each chapter begins on an odd page number. The facing page is always blank. This creates a lot of blank pages. I could render some line art on the facing pages, but I’m not taking that option at this point. Probably won’t.
My goal for the cover (as might everyone) is to catch a potential reader’s eye and signal something about the content. In this case, the Hemo Sapiens have violet eyes, so I thought that would make a unique image hook. The are open (obviously) to capture the Awakening aspect. The Greek letters on the overlay represent the science aspect. There are 5 versions of Hemo Sapiens so far, named Alpha, Beta, Gamma, Delta, and Epsilon by their creator. I’ve highlighted those characters in a blood red.
Speaking of blood, this is obviously captured in the colour choice and the dripping font of the subtitle. This is also reflected in the stylised O, but I don’t wish to explain the significance of the stylisation now.
As is the entire cover still in progress, so is the treatment of the title as I am playing with a few options. The novel is set in the near future, 2045, so I was thinking of conveying a future with a silver font face, but the gold felt somehow warmer. I wanted to hint at the dystopian angle by distressing the letters.
So, there’s my confession. If you have any comments on the design, I’d love to read them—for better and for worse.
Or is that ‘reading allowed?’ I’m all but done with my first draft of Hemo Sapiens, so I’m recording is chapter by chapter so I can listen to it. Listening uses different cognitive processes beyond the obvious sensory apparatus, so one catches different sorts of factors.
For me as an example, it helps me to capture pacing. When I scan my own work at this stage, I’ve read it so many times, it’s difficult to read critically. I sort of just gloss over the words in a perfunctory manner. Maybe that’s just me, but…
What I do is listen whilst I read along—sort of like in grade school: read silently whilst someone reads aloud. This is what it gets me:
Clumsy phrasing. It felt ok when I wrote it, but doesn’t read particularly well.
Repeat words written nearby. I try to avoid placing the same word in the same paragraph or to close in adjoining paragraphs. In this case, I used and character’s surname name near the end of a paragraph and then at the start at the next, It really caught my ear, so I changed the later one to a subject pronoun.
Spelling. Yep, spelling and grammar checkers still miss things. For me, some of my dialogue it either text-speak, BRB, or truncated, ‘That ain’t for nuttin”, so I often Word to ignore spelling until I’m ready. Though it isn’t necessarily revealed by the audio portion, I tend to track audio word by word, whilst I tend to read in paragraphs.
Typos and wrong words. Listening along yesterday, I noticed that I missed a pronoun change resulting from removing a male character and expanding a female character. A remnant ‘his’ needed to be amended to ‘her’.
Dense (or sparse) paragraphs. This is also about pacing. When listening, one can pick up that a passage just drags unnecessarily. It may need to be written, or it might just need to be broken up or re-punctuated. If it feels too fast that it might give the reader seizures, perhaps toss in a few dialogue tags or descriptors.
Perhaps I could come up with more, but these make my top of mind list.
I use ElevenLabs AI speech synthesis to convert my content from text to speech. I’ve written about my ElevenLabs wish list before. For the plan I use, I get 100,000 characters per month and can exceed that limit by purchasing 1,000 word blocks. I don’t the overage to be cost-effective, so I’d only ever use it in a pinch. The next plan is for a 500,000 word block, but the economics don’t work for me there either. Usually, it’s no big deal. Unless I am using it to narrate a novel, I just wait for the month to roll over and I can pick up where I left off. Fortuitously enough for me, I recorded 11 chapters yesterday before i ran out, and my plan refreshes today, so easy peasy.
ElevenLabs charges by the character, not by the word, which does make sense, but it’s not how I think about writing. I tend to think in terms of words or pages. When they say character count, they mean it—punctuation, quotes, and apostrophes, spaces, and carriage returns. I have discovered ways to reduce spaces, but you need to be careful, because it also uses punctuation to control some elements of prosody and delivery. For example, if you remove all of the commas and full stops, the delivery will be a ramble. For those who still double-space after double stops, this will cost you. Sometimes, when I’m feeling particularly frugal, I remove the carriage returns. They don’t seem to have any effect on the output, and it saves characters. It wouldn’t make for a great reading experience, but the AI doesn’t care.